
For the last couple of years, I’ve been using AWS Lambda to make Twitter and Mastodon bots. (Full disclosure: I work for a company that got acquired by Amazon a few years ago.) It’s more reliable than running them on a random box I own (for instance, like I have to do for Video Glitch Bot, @VidGBot, which requires a TV capture source), and surprisingly cheap (free in the intro tier, otherwise pennies a month). My public Lambdas generate and push content to Adjective-Noun-Bot (@AdjNounBot) and Enigma Ebooks (@enigma_ebooks), but I have some private ones to scrape daily sudoku puzzles, transform several RSS and iCal feeds, and pre-process podcast feeds. My latest bot is DangerousBot (@BotDangerous on Twitter and @DangerousBot@mastodon.cloud).
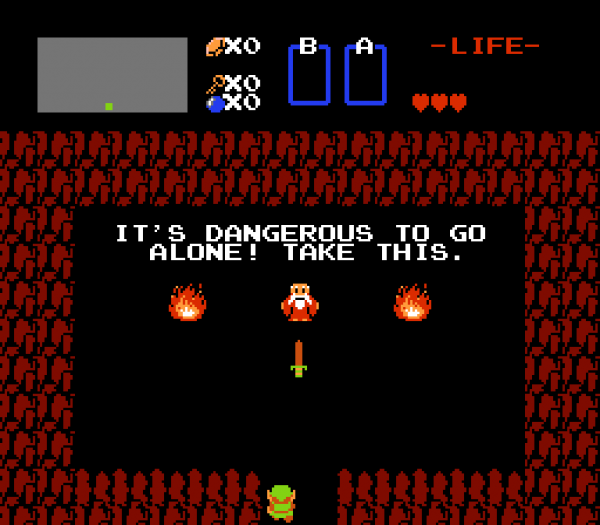
The idea for DangerousBot came to me from an old meme:

I thought it would be fun to take a random noun, send it through an image search, then attach it to the Zelda screenshot. The results look a bit like this:

Ovenware. For dubious food. 
Impersonate Mr. Bean
It sounds simple in concept, but the problem is that there are a lot of nouns in the world, and not all of them are interesting. You have an equal chance of getting orange or jackrabbit as you do neurodermatitis or phenazopyridine. So you need some heuristics in place.
I have an old Nutrimatic dictionary, which is an index of terms that appear on the English-language Wikipedia at least 5 times, sorted by number of occurrences. I sliced that down to the top 10,000 entries. But that contains adjectives, nouns, verbs, and everything else. I then intersected it with the Princeton WordNet list of nouns. This served as a solid basis of reasonable and common nouns.
The next step was to take one of those random words and push it through image search. The Google image search API got shut down a number of years back, but there is a Bing image search API that costs about $3/month (and which I was already paying because of the Adjective-Noun bot).
The key to the image search is to enable filtering on transparency. GIF and PNG images that have transparency have (usually…) had a certain amount of human-directed preprocessing and attention given to them. They are often product images. While an unrestrained image search on a given noun could turn up any random image, if you constrain it to only images with transparency, you typically get a better match. And it turns out that non-rectangular images look a little better in the Zelda screenshot. More sprite-like.
If a noun does not return an image result with transparency, we try for another noun.
Once we have a noun and an image with transparency, we start the compositing process. This starts with a base screenshot from Zelda, with the map, equipment, dialogue, and sword removed.

Next, we use ImageMagic (loaded into our Lambda via a layer) to scale the noun-image and insert it into the picture. Finally, we use the Emulogic font to add back not just the original text, but the Noun word itself to provide a little more character and context.
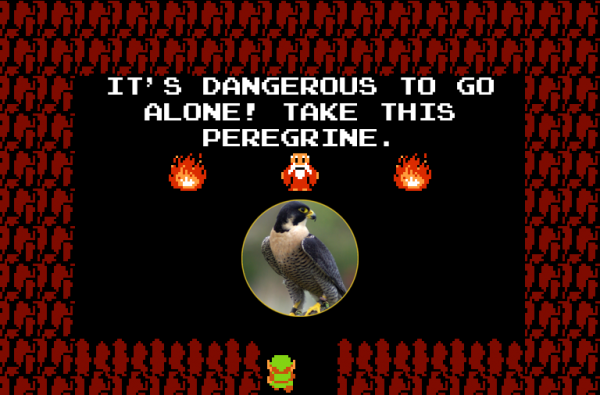
Finally, it uses python-twitter and mastodon.py to post to Twitter and Mastodon.
It’s been running for about two weeks and so far, so good. The main problem is that occasionally it picks up an image that’s mostly black (or similar dark color) on a transparent background. And you’d expect, that doesn’t show up on the game screen. I’m going to need to add a color histogram to filter out those images. Until then, just skim by those ones.
If you find this fun and interesting, please subscribe to @BotDangerous on Twitter or @DangerousBot@mastodon.cloud on Mastodon.
One thought on “It’s dangerous to go alone! Take this $NOUN”